Flume基础教程
Apache Flume教程
资料来源:Apache Flume - Introduction (tutorialspoint.com)
Flume是一个标准的、简单的、健壮的、灵活的、可扩展的工具,用于将从各种数据生产者(web服务器)中所产生的数据抽取到Hadoop中。在本教程中,我们将使用简单的说明性示例来解释Apache Flume的基础知识以及如何在实践中使用它。
1. Flume-简介
什么是Flume?
Apache Flume是一个工具/服务/数据抽取机制,用于从不同的数据来源收集和传输大量的流数据(如日志文件、事件等)到一个集中的数据存储。
Flume是一个高度可靠、分布式和可配置的工具。它主要用于从各种web服务器,将流数据(日志数据)传输到HDFS中。
下图1-1是Flume作用示例图:
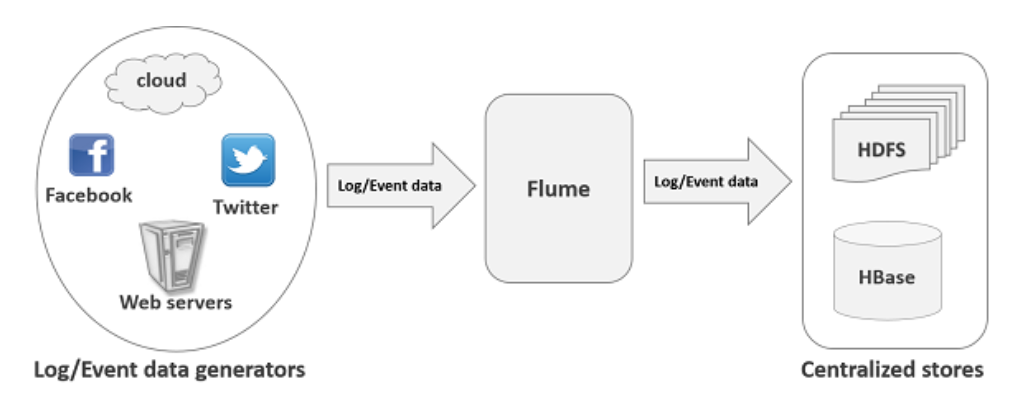
Flume的应用场景
假设电子商务web应用程序想要分析来自特定地区的客户行为。为此,他们需要将可用的日志数据移到Hadoop(HDFS)中进行分析。在这此场景,Apache Flume就可以解决这个日志数据移动工作。
Flume用于将应用服务器生成的日志数据以更高的速度移动到HDFS中。
Flume的优点
下面是使用Flume的优点
- 使用Apache Flume,我们可以将数据存储到任何集中式存储(HBase, HDFS)中。
- 当传入数据的速率超过可写入目标数据的速率时,Flume充当数据生产者和集中式存储之间的中介,并在它们之间提供稳定的数据流。
- Flume提供了上下文路由(contextual routing)的特性。
- Flume中的事务是基于通道的,其中为每个消息维护两个事务(一个发送方和一个接收方)。它保证可靠的消息传递。
- Flume是可靠的、容错的、可扩展的、易于管理的和可个性化定制的。
Flume的特点
以下是Flume的一些显著特点:
- Flume将来自多个web服务器的日志数据高效地抽取到一个集中存储(HDFS、HBase)中。
- 使用Flume,我们可以将来自多个服务器的数据及时地导入Hadoop。
- 除了日志文件,Flume还用于导入Facebook和Twitter等社交网站以及亚马逊和Flipkart等电子商务网站产生的大量事件数据。
- Flume支持大量的源和目标类型。
- Flume支持多跳流(multi-hop)、扇入扇(fan-in fan-out)出流、上下文路由等。
- Flume可以水平扩展
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 靓仔阿胜的博客!
 wechat
wechat alipay
alipay