黑马虚拟机环境搭建 1.网络设置 参考博客:
桥接模式设置参考博客
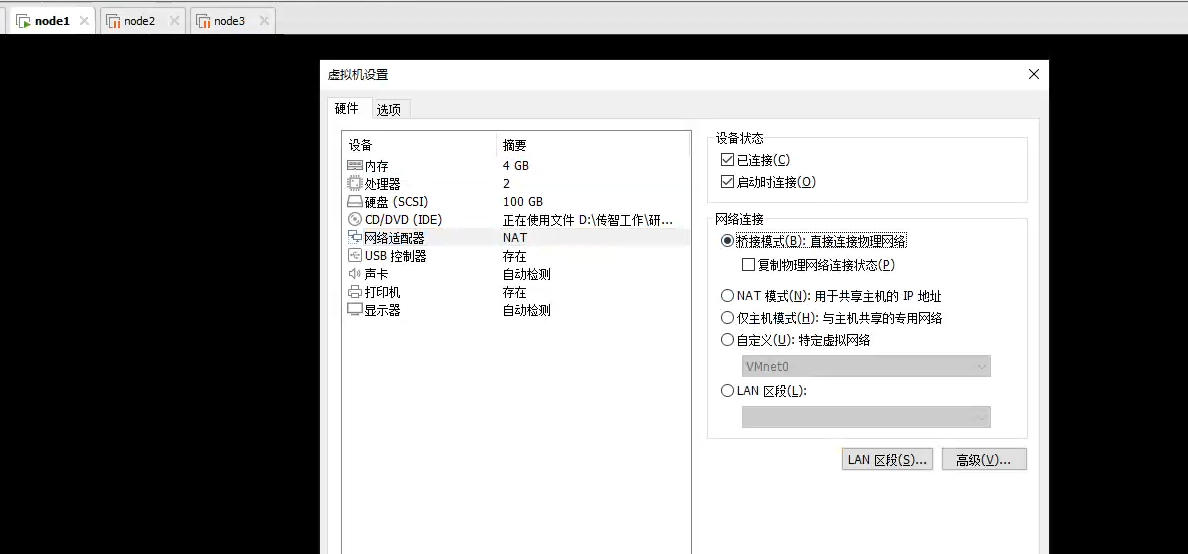
1.1 选择桥接模式
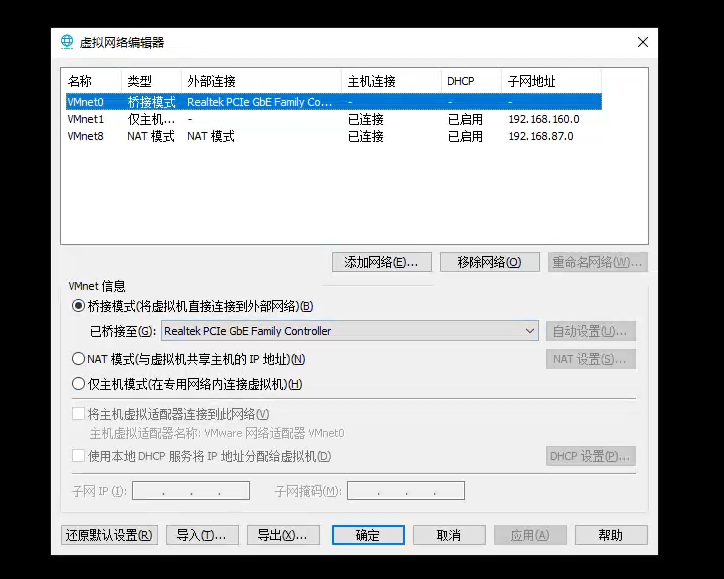
编辑Vmvare虚拟网络
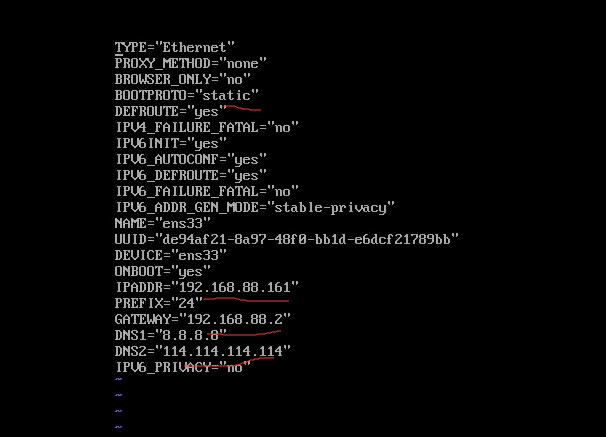
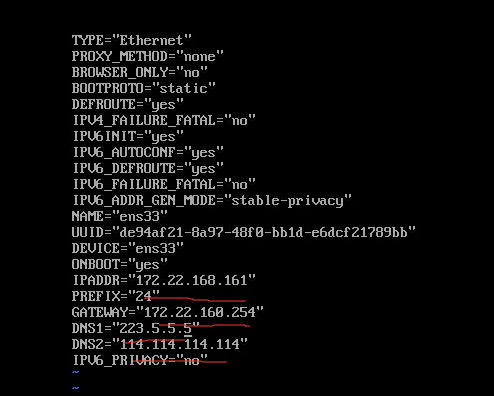
1.2 修改虚拟机ip 在根目录输入此命令:
1 2 vim /etc/sysconfig/network-scripts/ifcfg-ens33
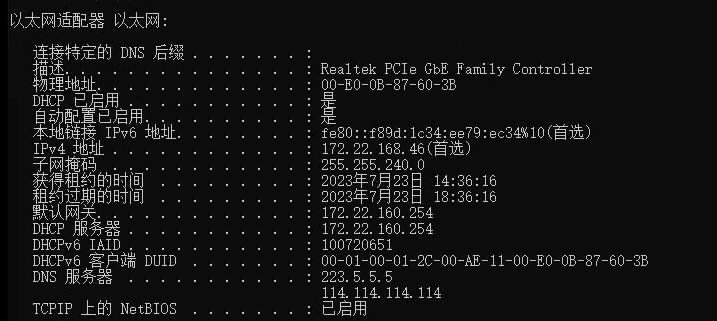
先在windows系统的cmd窗口输入 ipcong -all,得到
然后将虚拟机的文件修改为:
关闭防火墙:
1 2 3 4 systemctl stop firewalld systemctl disable firewalld.service
重启网络服务:
1 systemctl restart network.service
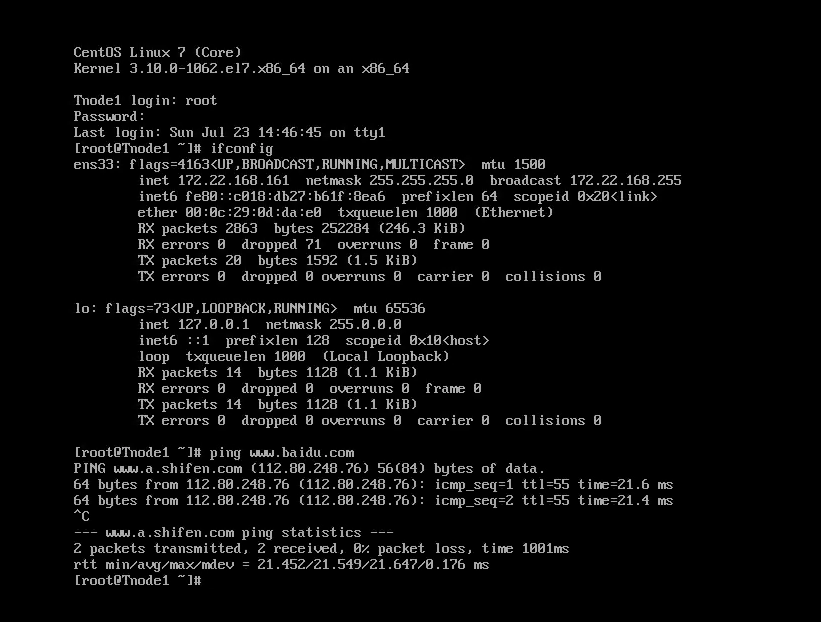
能ping通就OK 了:
2. 修改主机名和映射地址 2.1 修改主机名 在根目录输入:
修改为:
Tnode1
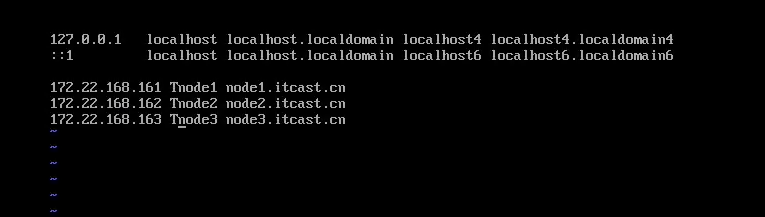
2.2 修改ip映射地址 在根目录输入:
修改为:
最后输入一下reboot重启一下就行了
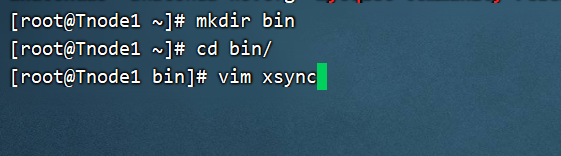
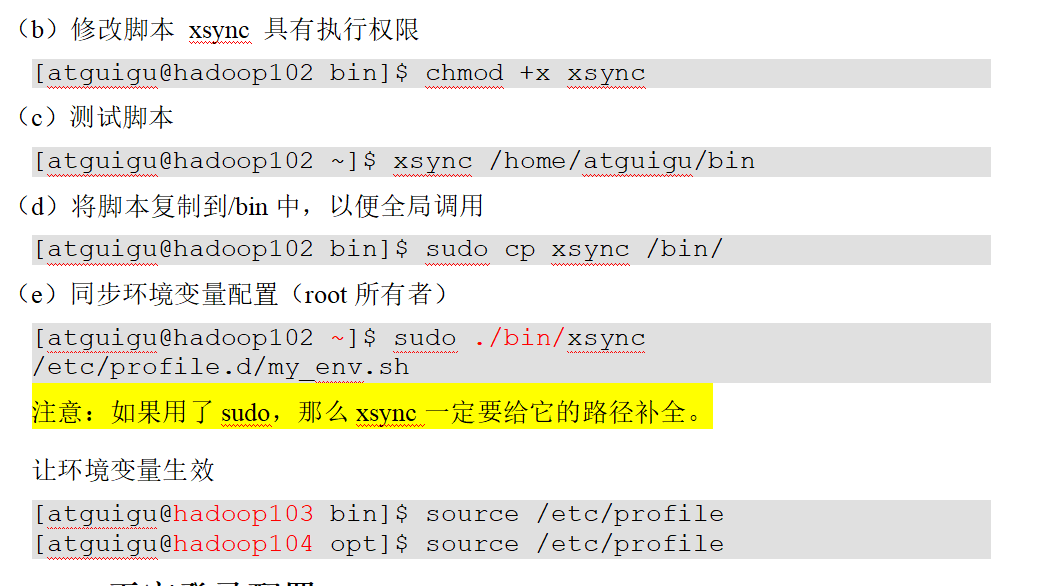
3. 编写分发脚本
插入:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # 1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi # 2. 遍历集群所有机器 for host in Tnode1 Tnode2 Tnode3 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done
4. 添加环境变量 输入:vim .bashrc
往后面添加:
1 2 export JAVA_HOME=/export/server/jdkexport PYSPARK_PYTHON=/root/anaconda3/envs/pyspark_env/bin/python3.8
5. 修改hadoop配置文件 5.1 修改core-site.xml 来到:
1 cd /export/server/hadoop/etc/hadoop/
修改:
1 2 3 4 5 <property > <name > fs.defaultFS</name > <value > hdfs://Tnode1:8020</value > </property >
5.2 修改hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 <property > <name > dfs.namenode.http-address</name > <value > Tnode1:9870</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > Tnode2:9868</value > </property >
5.2 修改yarn-site.xml 1 2 3 4 5 6 <property > <name > yarn.resourcemanager.hostname</name > <value > Tnode1</value > </property >
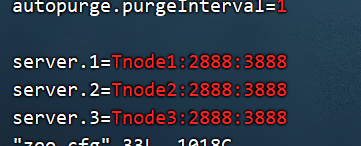
6. 启动集群 6.1 启动hadoop集群 6.2 启动zookeeper 修改
1 cd /export/server/zookeeper/conf
路径下的:
vim zoo.cfg
为:
1 2 3 4 5 /export/server/zookeeper/bin/zkServer.sh start /export/server/zookeeper/bin/zkServer.sh status
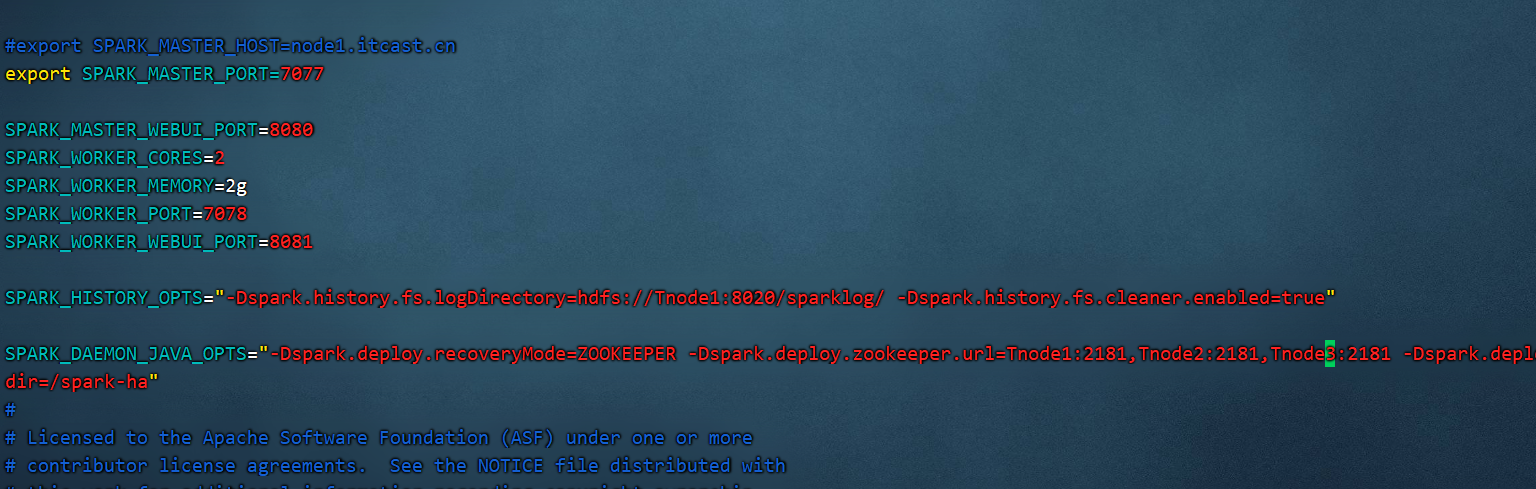
7 启动spark集群 修改spark-env.sh文件
找到:
1 cd /export/server/spark/conf
vim spark-env.sh
修改成如下配置:
7.1先在Tnode1启动所有集群 1 /export/server/spark/sbin/start-all.sh
7.2 再在Tnode2启动Maser集群 1 /export/server/spark/sbin/start-master.sh
7.3 开启历史服务器 1 /export/server/spark/sbin/start-history-server.sh
8. spark on hive 来到
1 2 cd /export/server/saprk/confvim hive-site.xml
修改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 <configuration > <property > <name > javax.jdo.option.ConnectionURL</name > <value > jdbc:mysql://Tnode1:3306/hive3?createDatabaseIfNotExist=true& useSSL=false</value > </property > <property > <name > javax.jdo.option.ConnectionDriverName</name > <value > com.mysql.jdbc.Driver</value > </property > <property > <name > javax.jdo.option.ConnectionUserName</name > <value > root</value > </property > <property > <name > javax.jdo.option.ConnectionPassword</name > <value > 123456</value > </property > <property > <name > hive.server2.thrift.bind.host</name > <value > Tnode1</value > </property > <property > <name > hive.metastore.warehouse.dir</name > <value > /user/hive/warehouse</value > </property > <property > <name > hive.metastore.uris</name > <value > thrift://Tnode3:9083</value > </property > <property > <name > hive.metastore.event.db.notification.api.auth</name > <value > false</value > </property > </configuration >
 wechat
wechat alipay
alipay