3.PySpark-SparkSQL
在Spark上运用SQL处理结构化数据
3.1 SparkSQL快速入门 3.1.1 什么是SparkSQL
SparkSQL是Spark的一个模块,用于处理海量结构化数据
限定:结构化数据处理
3.1.2 为什么要学习SparkSQL
SparkSQL是非常成熟的 海量结构化数据处理框架。
学习SparkSQL主要在2个点:
SparkSQL本身十分优秀, 支持SQL语言、性能强、可以自动优化、API简单、兼容HIVE等等
企业大面积在使用SparkSQL处理业务数据
离线开发
数仓搭建
科学计算
数据分析
3.1.3 SparkSQL特点
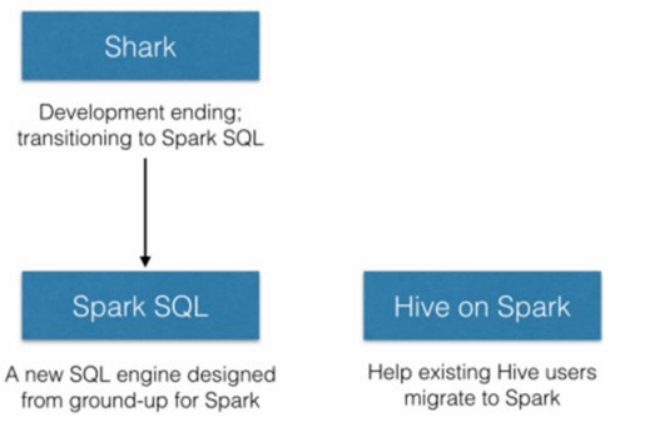
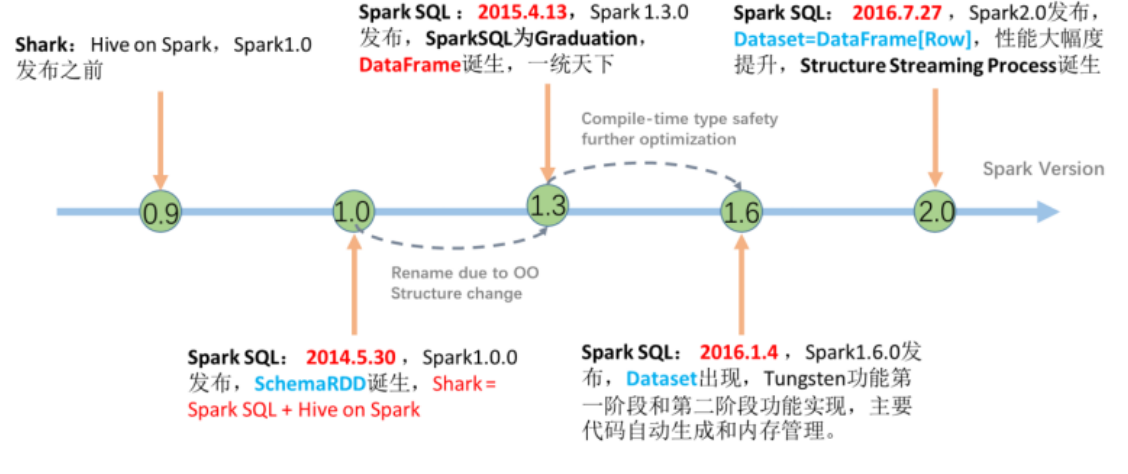
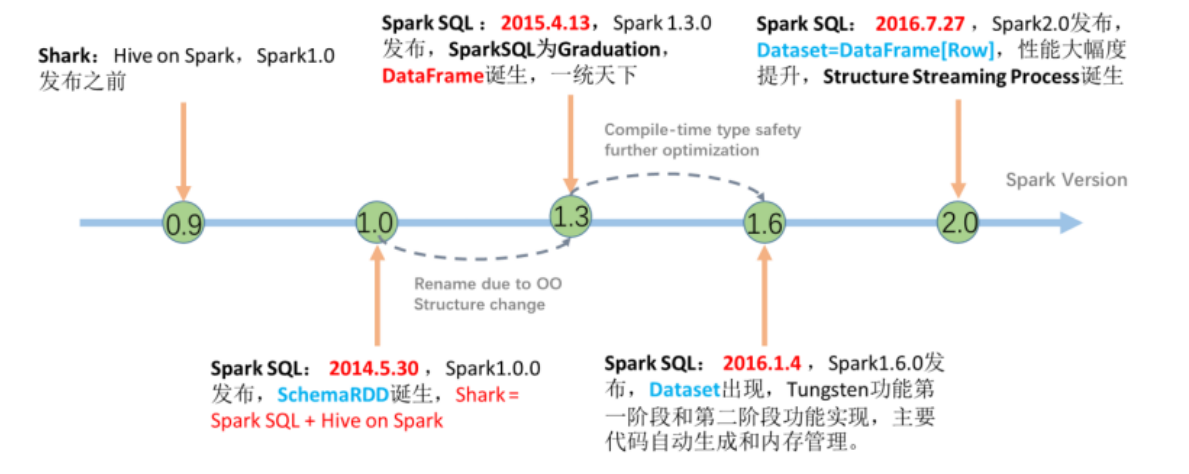
3.1.4 SparkSQL发展史
在许多年前(2012\2013左右)Hive逐步火热起来, 大片抢占分布式SQL计算市场
Spark作为通用计算框架, 也不可能放弃这一细分领域.
于是, Spark官方模仿Hive推出了Shark框架(Spark 0.9版本)
Shark框架是几乎100%模仿Hive, 内部的配置项\优化项等都是直接模仿而来.
不同点在于将执行引擎由MapReduce更换为了Spark.
因为Shark框架太模仿Hive, Hive是针对MR优化, 很多地方和SparkCore(RDD)水土不服, 最终被放弃
Spark官方下决心开发一个自己的分布式SQL引擎 也就是诞生了现在的SparkSQL
● 2014年 1.0正式发布
● 2015年 1.3 发布DataFrame数据结构, 沿用至今
● 2016年 1.6 发布Dataset数据结构(带泛型的DataFrame), 适用于支持泛型的语言(Java\Scala)
● 2016年 2.0 统一了Dataset 和 DataFrame, 以后只有Dataset了, Python用的DataFrame就是 没有泛型的Dataset
● 2019年 3.0 发布, 性能大幅度提升,SparkSQL变化不大
3.1.5 总结
SparkSQL用于处理大规模结构化数据的计算引擎
SparkSQL在企业中广泛使用,并性能极好,学习它不管是工作还是就业都有很大帮助
SparkSQL:使用简单、API统一、兼容HIVE、支持标准化JDBC和ODBC连接
SparkSQL 2014年正式发布,当下使用最多的2.0版,Spark发布于2016年,当下使用的最新3.0办发布于2019年
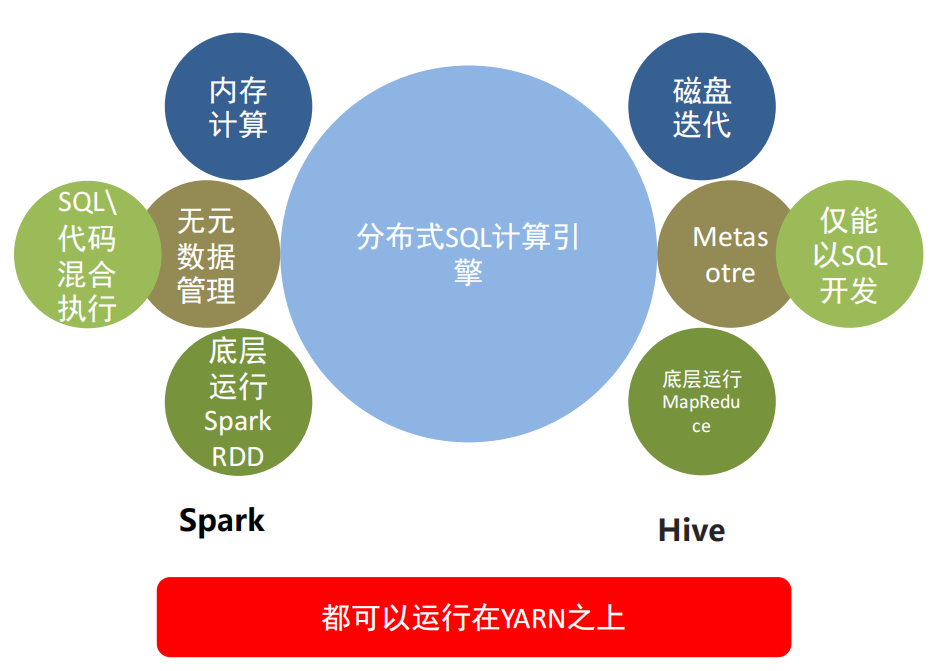
3.2 SparkSQL概述 3.2.1 SparkSQL和Hive的异同
Hive和Spark均是:“分布式SQL计算引擎” 均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。 目前,企业中使用Hive仍旧居多,但SparkSQL将会在很近的未来替代Hive成为分布式SQL计算市场的顶级
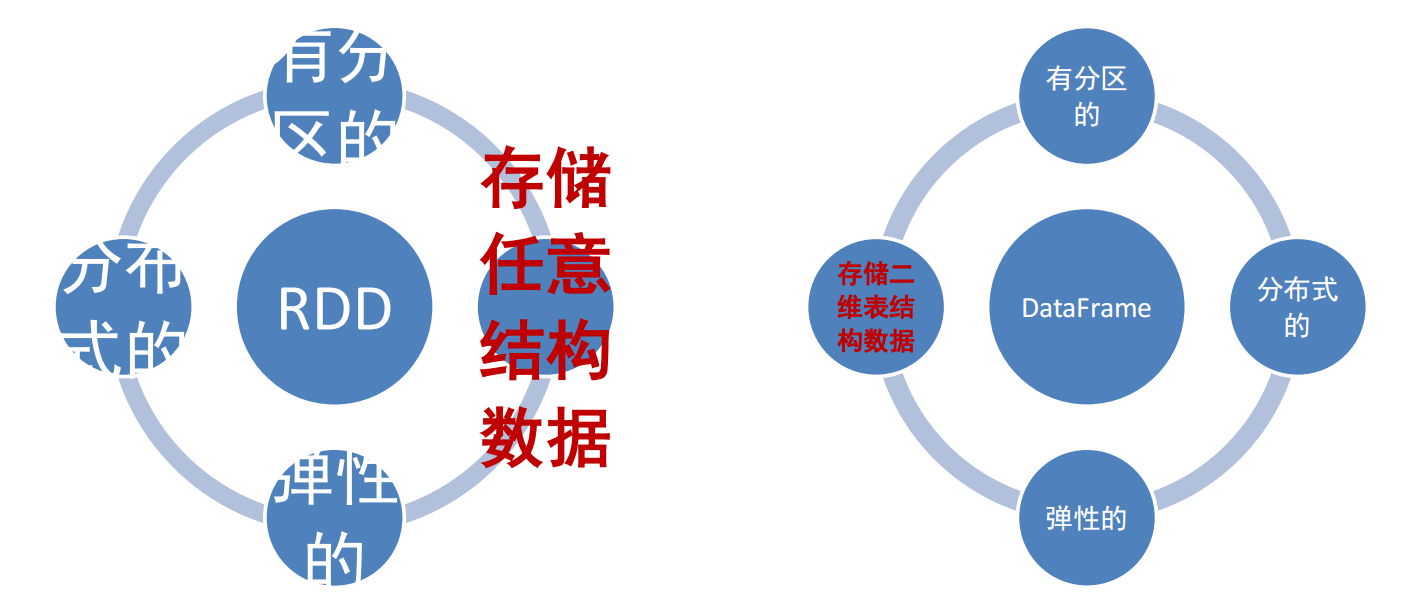
3.2.2 SparkSQL的数据抽象
3.2.3 SparkSQL数据抽象的发展
从SparkSQL的发展历史可以看到:
14年最早的数据抽象是:SchemaRDD(内部存储二维表数据结构的RDD),SchemaRDD就是魔改的RDD,将RDD支持的存储数据,限定
为二维表数据结构用以支持SQL查询。由于是魔改RDD,只是一个过渡产品,现已废弃。
15年发布DataFrame对象,基于Pandas的DataFrame(模仿)独立于RDD进行实现,将数据以二维表结构进行存储并支持分布式运行
16年发布DataSet对象,在DataFrame之上添加了泛型的支持,用以更好的支持Java和Scala这两个支持泛型的编程语言
16年,Spark2.0版本,将DataFrame和DataSet进行合并。其底层均是DataSet对象,但在Python和R语言到用时,显示为DataFrame对象。和老的DataFrame对象没有区别
3.2.4 DataFrame概述 DataFrame和RDD都是:弹性的、分布式的、数据集
只是,DataFrame存储的数据结构“限定”为:二维表结构化数据
而RDD可以存储的数据则没有任何限制,想处理什么就处理什么
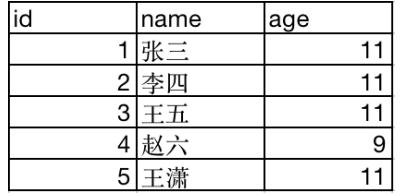
假定有如下数据集:
DataFrame按二维表存储:
RDD按数组对象存储:
DataFrame 是按照二维表格的形式存储数据
RDD则是存储对象本身
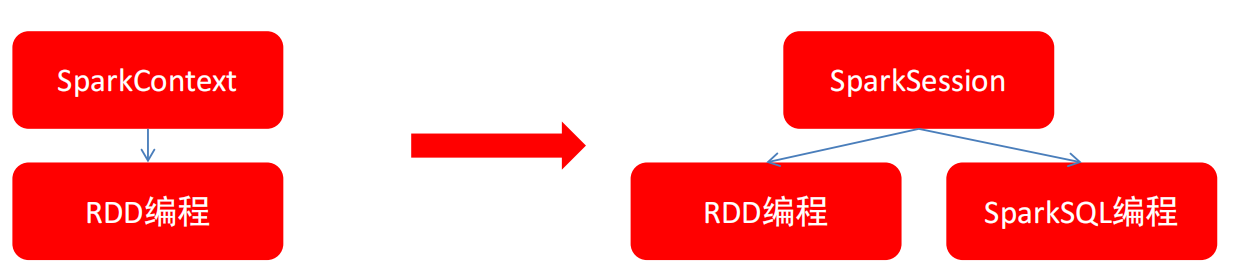
3.2.5 SparkSession对象 在RDD阶段,程序的执行入口对象是: SparkContext
在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
SparkSession对象可以:
用于SparkSQL编程作为入口对象
用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext
所以,我们后续的代码,执行环境入口对象,统一变更为SparkSession对象
现在,来体验一下构建执行环境入口对象:SparkSession
构建SparkSession核心代码
应该是.master(“local[*]”),见下文代码
3.2.6 SparkSQL HelloWorld 需求:读取文件,找出学科为“语文”的数据,并限制输出5条
where subject = ‘语文’ limit 5
代码演示:00_spark_session_create.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from pyspark.sql import SparkSessionif __name__ == '__main__' : spark = SparkSession.builder. \ appName("00_spark_session_create.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext df = spark.read.csv("../data/input/stu_score.txt" , sep=',' , header=False ) df2 = df.toDF("id" , "name" , "score" ) df2.printSchema() print ("读取并打印数据" ) df2.show() df2.createTempView("score" ) print ("SQL 风格结果:" ) spark.sql(""" select * from score where name ='语文' limit 5 """ ).show() print ("DSL 风格结果:" ) df2.where("name='语文'" ).limit(5 ).show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 root |-- id: string (nullable = true) |-- name: string (nullable = true) |-- score: string (nullable = true) 读取并打印数据 +---+----+-----+ | id|name|score| +---+----+-----+ | 1|语文| 99| | 2|语文| 99| | 3|语文| 99| | 4|语文| 99| | 5|语文| 99| | 6|语文| 99| | 7|语文| 99| | 8|语文| 99| | 9|语文| 99| | 10|语文| 99| | 11|语文| 99| | 12|语文| 99| | 13|语文| 99| | 14|语文| 99| | 15|语文| 99| | 16|语文| 99| | 17|语文| 99| | 18|语文| 99| | 19|语文| 99| | 20|语文| 99| +---+----+-----+ only showing top 20 rows SQL 风格结果: +---+----+-----+ | id|name|score| +---+----+-----+ | 1|语文| 99| | 2|语文| 99| | 3|语文| 99| | 4|语文| 99| | 5|语文| 99| +---+----+-----+ DSL 风格结果: +---+----+-----+ | id|name|score| +---+----+-----+ | 1|语文| 99| | 2|语文| 99| | 3|语文| 99| | 4|语文| 99| | 5|语文| 99| +---+----+-----+
3.2.7 总结
SparkSQL 和 Hive同样,都是用于大规模SQL分布式计算的计算框架,均可以运行在YARN之上,在企业中广泛被应用
SparkSQL的数据抽象为:SchemaRDD(废弃)、DataFrame(Python、R、Java、Scala)、DataSet(Java、Scala)。
DataFrame同样是分布式数据集,有分区可以并行计算,和RDD不同的是,DataFrame中存储的数据结构是以表格形式组织的,方便进行SQL计算
DataFrame对比DataSet基本相同,不同的是DataSet支持泛型特性,可以让Java、Scala语言更好的利用到。
SparkSession是2.0后推出的新执行环境入口对象,可以用于RDD、SQL等编程
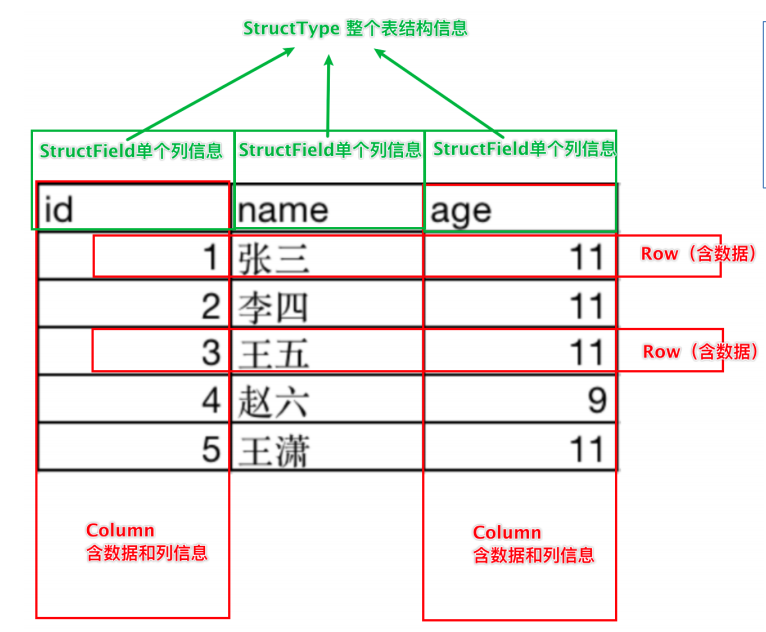
3.3 DataFrame入门 3.3.1 DataFrame的组成 DataFrame是一个二维表结构, 那么表格结构就有无法绕开的三个点:
比如,在MySQL中的一张表:
由许多行组成
数据也被分成多个列
表也有表结构信息(列、列名、列类型、列约束等)
基于这个前提,DataFrame的组成如下:
在结构层面:
StructType对象描述整个DataFrame的表结构StructField对象描述一个列的信息
在数据层面:
Row对象记录一行数据Column对象记录一列数据并包含列的信息
如图, 在表结构层面,DataFrame的表结构由StructType描述,如下图:
一个StructField记录:列名、列类型、列是否运行为空
多个StructField组成一个StructType对象。
一个StructType对象可以描述一个DataFrame:有几个列、每个列的名字和类型、每个列是否为空
同时,一行数据描述为Row对象,如Row(1, 张三, 11)
一列数据描述为Column对象,Column对象包含一列数据和列的信息
Row、Column、StructType、StructField的编程我们在后面编码阶段会接触
3.3.2 DataFrame的代码构建 3.3.2.1 基于RDD方式1 DataFrame对象可以从RDD转换而来,都是分布式数据集,其实就是转换一下内部存储的结构,转换为二维表结构
将RDD转换为DataFrame方式1:
调用spark
1 2 3 4 5 6 rdd = sc.textFile("../data/sql/people.txt" ).\ map (lambda x: x.split(',' )).\map (lambda x: [x[0 ], int (x[1 ])]) df = spark.createDataFrame(rdd, schema = ['name' , 'age' ])
通过SparkSession对象的createDataFrame方法来将RDD转换为DataFrame
这里只传入列名称,类型从RDD中进行推断,是否允许为空,默认为允许(True)
完整代码演示:01_dataframe_create1.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from pyspark.sql import SparkSessionif __name__ == '__main__' : spark = SparkSession.builder. \ appName("01_dataframe_create1.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.textFile("../data/input/sql/people.txt" ). \ map (lambda x: x.split("," )). \ map (lambda x: (x[0 ], int (x[1 ]))) df = spark.createDataFrame(rdd, schema=['name' , 'age' ]) df.printSchema() df.show(20 , False ) df.createOrReplaceTempView("people" ) spark.sql("select * from people where age < 30" ).show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 root |-- name: string (nullable = true) |-- age: long (nullable = true) +-------+---+ |name |age| +-------+---+ |Michael|29 | |Andy |30 | |Justin |19 | +-------+---+ +-------+---+ | name|age| +-------+---+ |Michael| 29| | Justin| 19| +-------+---+
3.3.2.2基于RDD方式2 将RDD转换为DataFrame方式2:
通过StructType对象来定义DataFrame的“表结构”转换RDD
1 2 3 4 5 6 7 8 9 10 11 12 13 rdd = sc.textFile("../data/sql/stu_score.txt" ).\ map (lambda x:x.split(',' )).\map (lambda x:(int (x[0 ]), x[1 ], int (x[2 ])))schema = StructType().\ add("id" , IntegerType(), nullable=False ).\ add("name" , StringType(), nullable=True ).\ add("score" , IntegerType(), nullable=False ) df = spark.createDataFrame(rdd, schema)
完整代码演示:02_dataframe_create2.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("02_dataframe_create2.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.textFile("../data/input/sql/people.txt" ). \ map (lambda x: x.split("," )). \ map (lambda x: (x[0 ], int (x[1 ]))) schema = StructType().add("name" ,StringType(),nullable=True ).\ add("age" ,IntegerType(),nullable=False ) df = spark.createDataFrame(rdd,schema=schema) df.printSchema() df.show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 root |-- name: string (nullable = true) |-- age: integer (nullable = false) +-------+---+ | name|age| +-------+---+ |Michael| 29| | Andy| 30| | Justin| 19| +-------+---+
3.3.2.3 基于RDD方式3 将RDD转换为DataFrame方式3:使用RDD的toDF方法转换RDD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 schema = StructType().\ add("id" , IntegerType(), nullable=False ).\ add("name" , StringType(), nullable=True ).\ add("score" , IntegerType(), nullable=False ) df = rdd.toDF(['id' , 'subject' , 'score' ]) df.printSchema() df.show() df = rdd.toDF(schema) df.printSchema() df.show()
完整代码演示:03_dataframe_create3.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("03_dataframe_create3.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.textFile("../data/input/sql/people.txt" ). \ map (lambda x: x.split("," )). \ map (lambda x: (x[0 ], int (x[1 ]))) df1 = rdd.toDF(["name" , "age" ]) df1.printSchema() df1.show() schema = StructType().add("name" , StringType(), nullable=True ). \ add("age" , IntegerType(), nullable=False ) df2 = rdd.toDF(schema=schema) df2.printSchema() df2.show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 root |-- name: string (nullable = true) |-- age: long (nullable = true) +-------+---+ | name|age| +-------+---+ |Michael| 29| | Andy| 30| | Justin| 19| +-------+---+ root |-- name: string (nullable = true) |-- age: integer (nullable = false) +-------+---+ | name|age| +-------+---+ |Michael| 29| | Andy| 30| | Justin| 19| +-------+---+
3.3.2.4 基于Pandas的DF 将Pandas的DataFrame对象,转变为分布式的SparkSQL DataFrame对象
1 2 3 4 5 6 7 8 pdf = pd.DataFrame({ "id" : [1 , 2 , 3 ],"name" : ["张大仙" , '王晓晓' , '王大锤' ],"age" : [11 , 11 , 11 ]}) df = spark.createDataFrame(pdf)
完整代码演示:04_dataframe_create4.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeimport pandas as pdif __name__ == '__main__' : spark = SparkSession.builder. \ appName("04_dataframe_create4.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext pdf = pd.DataFrame( { "id" : [1 , 2 , 3 ], "name" : ["靓仔" , "吊毛" , "如花" ], "age" : [11 , 21 , 11 ] } ) df = spark.createDataFrame(pdf) df.printSchema() df.show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 root |-- id: long (nullable = true) |-- name: string (nullable = true) |-- age: long (nullable = true) +---+----+---+ | id|name|age| +---+----+---+ | 1|靓仔| 11| | 2|吊毛| 21| | 3|如花| 11| +---+----+---+
3.3.2.5 读取外部数据 通过SparkSQL的统一API进行数据读取构建DataFrame
统一API示例代码:
1 2 3 4 sparksession.read.format ("text|csv|json|parquet|orc|avro|jdbc|......" ) .option("K" , "V" ) .schema(StructType | String) .load("被读取文件的路径, 支持本地文件系统和HDFS" )
读取text数据源 :
使用format(“text”)读取文本数据
读取到的DataFrame只会有一个列,列名默认称之为:value
示例代码:
1 2 3 4 schema = StructType().add("data" , StringType(), nullable=True ) df = spark.read.format ("text" )\ .schema(schema)\ .load("../data/sql/people.txt" )
完整代码演示:05_dataframe_create5_text.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeimport pandas as pdif __name__ == '__main__' : spark = SparkSession.builder. \ appName("05_dataframe_create5_text.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext schema = StructType().add("data" , StringType(), nullable=True ) df = spark.read.format ("text" ). \ schema(schema=schema). \ load("../data/input/sql/people.txt" ) df.printSchema() df.show()
输出结果:
1 2 3 4 5 6 7 8 9 10 root |-- data: string (nullable = true) +-----------+ | data| +-----------+ |Michael, 29| | Andy, 30| | Justin, 19| +-----------+
读取json数据源
使用format("json")读取json数据
示例代码:
1 2 3 4 5 df = spark.read.format ("json" ).\ load("../data/sql/people.json" ) df.printSchema() df.show()
完整代码演示:06_dataframe_create6_json.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeimport pandas as pdif __name__ == '__main__' : spark = SparkSession.builder. \ appName("06_dataframe_create6_json.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext df = spark.read.format ("json" ).load("../data/input/sql/people.json" ) df.printSchema() df.show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 root |-- age: long (nullable = true) |-- name: string (nullable = true) +----+-------+ | age| name| +----+-------+ |null|Michael| | 30| Andy| | 19| Justin| +----+-------+
读取csv数据源
使用format(“csv”)读取csv数据
示例代码:
1 2 3 4 5 6 7 8 df = spark.read.format ("csv" )\ .option("sep" , ";" )\ .option("header" , False )\ .option("encoding" , "utf-8" )\ .schema("name STRING, age INT, job STRING" )\ .load("../data/sql/people.csv" ) df.printSchema() df.show()
完整代码演示:07_dataframe_create7_csv.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeimport pandas as pdif __name__ == '__main__' : spark = SparkSession.builder. \ appName("07_dataframe_create7_csv.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext df = spark.read.format ("csv" ). \ option("sep" , ";" ). \ option("header" , True ). \ option("encoding" , "utf-8" ). \ schema("name STRING,age INT,job STRING" ). \ load("../data/input/sql/people.csv" ) df.printSchema() df.show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 root |-- name: string (nullable = true) |-- age: integer (nullable = true) |-- job: string (nullable = true) +-----+----+---------+ | name| age| job| +-----+----+---------+ |Jorge| 30|Developer| | Bob| 32|Developer| | Ani| 11|Developer| | Lily| 11| Manager| | Put| 11|Developer| |Alice| 9| Manager| |Alice| 9| Manager| |Alice| 9| Manager| |Alice| 9| Manager| |Alice|null| Manager| |Alice| 9| null| +-----+----+---------+
读取parquet数据源
使用format(“parquet”)读取parquet数据
示例代码:
1 2 3 4 5 df = spark.read.format ("parquet" ).\ load("../data/sql/users.parquet" ) df.printSchema() df.show()
完整代码演示:08_dataframe_create8_parquet.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeimport pandas as pdif __name__ == '__main__' : spark = SparkSession.builder. \ appName("08_dataframe_create8_parquet.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext df = spark.read.format ("parquet" ).load("../data/input/sql/users.parquet" ) df.printSchema() df.show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 root |-- name: string (nullable = true) |-- favorite_color: string (nullable = true) |-- favorite_numbers: array (nullable = true) | |-- element: integer (containsNull = true) +------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ |Alyssa| null| [3, 9, 15, 20]| | Ben| red| []| +------+--------------+----------------+
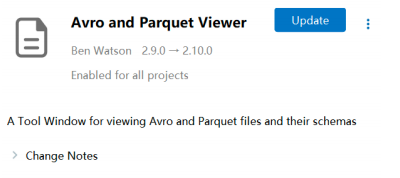
parquet: 是Spark中常用的一种列式存储文件格式,和Hive中的ORC差不多, 他俩都是列存储格式
parquet对比普通的文本文件的区别:
Parquet文件不能直接打开查看,如果想要查看内容可以在PyCharm中安装如下插件来查看:
3.3.3 DataFrame的入门操作 DataFrame支持两种风格进行编程,分别是:
DSL 语法风格:
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如:df.where().limit()
SQL 语法风格:
SQL风格就是使用SQL语句处理DataFrame的数据
比如:spark.sql(“SELECT * FROM xxx)
3.3.3.1 DSL风格 DSL-show方法
功能:展示DataFrame中的数据, 默认展示20条
语法:
1 2 3 df.show(参数1 , 参数2 ) - 参数1 : 默认是20 , 控制展示多少条 - 参数2 : 是否截断列, 默认只输出20 个字符的长度, 过长不显示, 要显示的话 请填入 truncate = True
如图,某个df.show后的展示结果:
DSL-printSchema方法
功能:打印输出df的schema信息
语法:
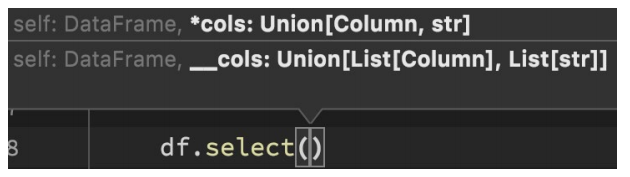
DSL-select
功能:选择DataFrame中的指定列(通过传入参数进行指定)
语法:
可传递:
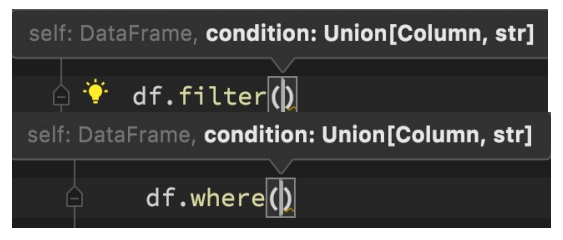
DLS-filter和where
功能:过滤DataFrame内的数据,返回一个过滤后的DataFrame
语法:
df.filter()
df.where()
where和filter功能上是等价的
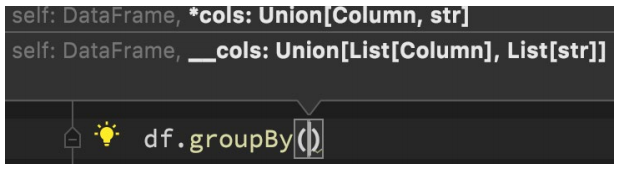
DSL-groupBy分组
功能:按照指定的列进行数据的分组, 返回值是GroupedData对象
语法:
df.groupBy()
传入参数和select一样,支持多种形式,不管怎么传意思就是告诉spark按照哪个列分组
GroupedData对象
GroupedData对象是一个特殊的DataFrame数据集,其类全名:<class 'pyspark.sql.group.GroupedData'>,这个对象是经过groupBy后得到的返回值, 内部记录了 以分组形式存储的数据,GroupedData对象其实也有很多API,比如前面的count方法就是这个对象的内置方法。除此之外,像:min、max、avg、sum、等等许多方法都存在,后续会再次使用它。
代码演示:09_dataframe_process_dsl.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeimport pandas as pdif __name__ == '__main__' : spark = SparkSession.builder. \ appName("09_dataframe_process_dsl.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext df = spark.read.format ("csv" ).\ schema("id INT,subject STRING,score INT" ).\ load("../data/input/sql/stu_score.txt" ) id_column = df['id' ] subject_column = df['subject' ] df.select(["id" ,'subject' ]).show() df.filter ("score < 99" ).show() df.where("score < 99" ).show() df.groupBy("subject" ).count().show() r = df.groupBy("subject" ) print (type (r)) print (r.max ().show()) print (r.min ().show())
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 +---+-------+ | id|subject| +---+-------+ | 1| 语文| | 2| 语文| | 3| 语文| | 4| 语文| | 5| 语文| | 6| 语文| | 7| 语文| | 8| 语文| | 9| 语文| | 10| 语文| | 11| 语文| | 12| 语文| | 13| 语文| | 14| 语文| | 15| 语文| | 16| 语文| | 17| 语文| | 18| 语文| | 19| 语文| | 20| 语文| +---+-------+ only showing top 20 rows +---+-------+-----+ | id|subject|score| +---+-------+-----+ | 1| 数学| 96| | 2| 数学| 96| | 3| 数学| 96| | 4| 数学| 96| | 5| 数学| 96| | 6| 数学| 96| | 7| 数学| 96| | 8| 数学| 96| | 9| 数学| 96| | 10| 数学| 96| | 11| 数学| 96| | 12| 数学| 96| | 13| 数学| 96| | 14| 数学| 96| | 15| 数学| 96| | 16| 数学| 96| | 17| 数学| 96| | 18| 数学| 96| | 19| 数学| 96| | 20| 数学| 96| +---+-------+-----+ only showing top 20 rows +---+-------+-----+ | id|subject|score| +---+-------+-----+ | 1| 数学| 96| | 2| 数学| 96| | 3| 数学| 96| | 4| 数学| 96| | 5| 数学| 96| | 6| 数学| 96| | 7| 数学| 96| | 8| 数学| 96| | 9| 数学| 96| | 10| 数学| 96| | 11| 数学| 96| | 12| 数学| 96| | 13| 数学| 96| | 14| 数学| 96| | 15| 数学| 96| | 16| 数学| 96| | 17| 数学| 96| | 18| 数学| 96| | 19| 数学| 96| | 20| 数学| 96| +---+-------+-----+ only showing top 20 rows +-------+-----+ |subject|count| +-------+-----+ | 英语| 30| | 语文| 30| | 数学| 30| +-------+-----+ <class 'pyspark.sql.group.GroupedData'> +-------+-------+----------+ |subject|max(id)|max(score)| +-------+-------+----------+ | 英语| 33| 99| | 语文| 30| 99| | 数学| 30| 96| +-------+-------+----------+ None +-------+-------+----------+ |subject|min(id)|min(score)| +-------+-------+----------+ | 英语| 1| 99| | 语文| 1| 99| | 数学| 1| 96| +-------+-------+----------+ None
3.3.3.2 SQL风格 SQL风格语法-注册DataFrame成为表 :
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中,使用spark.sql() 来执行SQL语句查询,结果返回一个DataFrame。如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
SQL风格语法-使用SQL查询 :
注册好表后,可以通过:
sparksession.sql(sql语句)来执行sql查询
返回值是一个新的df
示例:
pyspark.sql.functions包 :
PySpark提供了一个包: pyspark.sql.functions
这个包里面提供了 一系列的计算函数供SparkSQL使用,如何用呢?
导包
from pyspark.sql import functions as F
然后就可以用F对象调用函数计算了。这些功能函数, 返回值多数都是Column对象:
示例 :
代码演示:10_dataframe_process_sql.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StringType, IntegerTypeimport pandas as pdif __name__ == '__main__' : spark = SparkSession.builder. \ appName("10_dataframe_process_sql.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext df = spark.read.format ("csv" ). \ schema("id INT,subject STRING,score INT" ). \ load("../data/input/sql/stu_score.txt" ) df.createTempView("score" ) df.createOrReplaceTempView("score_2" ) df.createGlobalTempView("score_3" ) spark.sql("select subject,count(*) as cnt from score group by subject" ).show() spark.sql("select subject,count(*) as cnt from score_2 group by subject" ).show() spark.sql("select subject,count(*) as cnt from global_temp.score_3 group by subject" ).show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 +-------+---+ |subject|cnt| +-------+---+ | 英语| 30| | 语文| 30| | 数学| 30| +-------+---+ +-------+---+ |subject|cnt| +-------+---+ | 英语| 30| | 语文| 30| | 数学| 30| +-------+---+ +-------+---+ |subject|cnt| +-------+---+ | 英语| 30| | 语文| 30| | 数学| 30| +-------+---+
3.3.4 词频统计案例 我们来完成一个单词计数需求,使用DSL和SQL两种风格来实现。
代码演示:11_wordcount_demo.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Fif __name__ == '__main__' : spark = SparkSession.builder. \ appName("11_wordcount_demo.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.textFile("../data/input/words.txt" ). \ flatMap(lambda x: x.split(" " )). \ map (lambda x: [x]) df = rdd.toDF(["word" ]) df.createTempView("words" ) spark.sql("select word,count(*) as cnt from words group by word order by cnt desc " ).show() df = spark.read.format ("text" ).load("../data/input/words.txt" ) df2 = df.withColumn("value" , F.explode(F.split(df['value' ], " " ))) df2.groupBy("value" ). \ count(). \ withColumnRenamed("value" , "word" ). \ withColumnRenamed("count" , "cnt" ). \ orderBy("cnt" , ascending=False ). \ show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 +------+---+ | word|cnt| +------+---+ | hello| 3| | spark| 1| | flink| 1| |hadoop| 1| +------+---+ +------+---+ | word|cnt| +------+---+ | hello| 3| | spark| 1| |hadoop| 1| | flink| 1| +------+---+
3.5 电影数据分析 需求:
查询用户平均分
查询电影平均分
查询大于平均分的电影的数量
查询高分电影中(>3)打分次数最多的用户,并求出此人打的平均分
查询每个用户文档平均打分,最低打分,最高打分
查询被评分超过100次的电影,的平均分排名Top100
代码演示:12_movie_demo.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 import timefrom pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("12_movie_demo.py" ). \ master("local[*]" ). \ config("spark.sql.shuffle.partitions" , 2 ). \ getOrCreate() sc = spark.sparkContext """ spark.sql.shuffle.partitions 参数指的是,在sql计算中,shuffle算子阶段默认的分区数是200个, 对于集群模式来说,200个默认也算比较合适 如果在local下运行,200个很多,在调度上会带来额外损耗 所以在local下建议修改比较低 比如2/4/10均可 这个参数和Spark RDD中设置并行度的参数 是相互独立的 """ schema = StructType().add("user_id" , StringType(), nullable=True ). \ add("movie_id" , IntegerType(), nullable=True ). \ add("rank" , IntegerType(), nullable=True ). \ add("ts" , StringType(), nullable=True ) df = spark.read.format ("csv" ). \ option("sep" , "\t" ). \ option("header" , False ). \ option("encoding" , "utf-8" ). \ schema(schema=schema). \ load("../data/input/sql/u.data" ) df.groupBy("user_id" ). \ avg("rank" ). \ withColumnRenamed("avg(rank)" , "avg_rank" ). \ withColumn("avg_rank" , F.round ("avg_rank" , 2 )). \ orderBy("avg_rank" , ascending=False ). \ show() print ("*" * 200 ) df.createTempView("movie" ) spark.sql(""" select movie_id,round(avg(rank),2) as avg_rank from movie group by movie_id order by avg_rank desc """ ).show() print ("*" * 200 ) above_average_scores = df.where(df['rank' ] > df.select(F.avg(df['rank' ])).first()['avg(rank)' ]).count() print ("大于平均分电影数量数:" , above_average_scores) print ("*" * 200 ) user_id = df.where("rank>3" ). \ groupBy("user_id" ). \ count(). \ withColumnRenamed("count" , "cnt" ). \ orderBy("cnt" , ascending=False ). \ first()["user_id" ] print (user_id) df.filter (df['user_id' ] == user_id). \ select(F.round (F.avg("rank" ), 2 )).show() print ("*" * 200 ) df.groupBy("user_id" ). \ agg( F.round (F.avg("rank" ), 2 ).alias("avg_rank" ), F.min ("rank" ).alias("min_rank" ), F.max ("rank" ).alias("max_rank" ) ).show() print ("*" * 200 ) df.groupBy("movie_id" ). \ agg( F.count("movie_id" ).alias("cnt" ), F.round (F.avg("rank" ), 2 ).alias("avg_rank" ) ).where("cnt > 100" ). \ orderBy("avg_rank" , ascending=False ). \ limit(10 ). \ show() time.sleep(100000 ) """ 1. agg: 它是GroupData对象的API,作用是 在里面可以写多个聚合 2. alias: 它是Column对象的API,可以针对一个列 进行改名 3. withColumnRenamed:它是DataFrame的API,可以对DF中的列进行改名,一次改一个列,改多个列 可以链式调用 4. orderBy:DataFrame的API,进行排序,参数1是被排序的列,参数2是 升序(True) 或降序 False 5. first:DataFrame的API,取出DF的第一行数据,返回结果是Row对象 # Row对象 就是一个数组,你可以通过row['列名']来取出当前行中,某一列的具体数值, # 返回值不再是DF或者GroupData或者Column,而是具体的字符串或者数字 """
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 +-------+--------+ |user_id|avg_rank| +-------+--------+ | 849| 4.87| | 688| 4.83| | 507| 4.72| | 628| 4.7| | 928| 4.69| | 118| 4.66| | 907| 4.57| | 686| 4.56| | 427| 4.55| | 565| 4.54| | 469| 4.53| | 850| 4.53| | 225| 4.52| | 330| 4.5| | 477| 4.46| | 242| 4.45| | 636| 4.45| | 583| 4.44| | 252| 4.43| | 767| 4.43| +-------+--------+ only showing top 20 rows ******************************************************************************************************************************************************************************************************** +--------+--------+ |movie_id|avg_rank| +--------+--------+ | 1500| 5.0| | 1201| 5.0| | 1189| 5.0| | 1536| 5.0| | 1293| 5.0| | 1653| 5.0| | 1599| 5.0| | 1467| 5.0| | 1122| 5.0| | 814| 5.0| | 1449| 4.63| | 119| 4.5| | 1398| 4.5| | 1594| 4.5| | 1642| 4.5| | 408| 4.49| | 318| 4.47| | 169| 4.47| | 483| 4.46| | 64| 4.45| +--------+--------+ only showing top 20 rows ******************************************************************************************************************************************************************************************************** 大于平均分电影数量数: 55375 ******************************************************************************************************************************************************************************************************** 450 +-------------------+ |round(avg(rank), 2)| +-------------------+ | 3.86| +-------------------+ ******************************************************************************************************************************************************************************************************** +-------+--------+--------+--------+ |user_id|avg_rank|min_rank|max_rank| +-------+--------+--------+--------+ | 186| 3.41| 1| 5| | 244| 3.65| 1| 5| | 200| 4.03| 2| 5| | 210| 4.06| 2| 5| | 303| 3.37| 1| 5| | 122| 3.98| 1| 5| | 194| 2.96| 1| 5| | 291| 3.69| 1| 5| | 119| 3.95| 1| 5| | 167| 3.38| 1| 5| | 299| 3.46| 1| 5| | 102| 2.62| 1| 4| | 160| 3.92| 1| 5| | 225| 4.52| 2| 5| | 290| 3.35| 1| 5| | 97| 4.16| 1| 5| | 157| 3.78| 1| 5| | 201| 3.03| 1| 5| | 287| 4.11| 1| 5| | 246| 2.93| 1| 5| +-------+--------+--------+--------+ only showing top 20 rows ******************************************************************************************************************************************************************************************************** +--------+---+--------+ |movie_id|cnt|avg_rank| +--------+---+--------+ | 408|112| 4.49| | 169|118| 4.47| | 318|298| 4.47| | 483|243| 4.46| | 64|283| 4.45| | 603|209| 4.39| | 12|267| 4.39| | 50|583| 4.36| | 178|125| 4.34| | 427|219| 4.29| +--------+---+--------+
3.3.6 SparkSQL Shuffle 分区数目 运行上述程序时,查看WEB UI监控页面发现,某个Stage中有200个Task任务,也就是说RDD有200分区Partition。
原因:在SparkSQL中当Job中产生Shuffle时,默认的分区数(spark.sql.shuffle.partitions) 为200,在实际项目中要合理的设置。
可以设置在:
配置文件: conf/spark-defaults.conf: spark.sql.shuffle.partitions 100
在客户端提交参数中:bin/spark-submit –conf “spark.sql.shuffle.partitions = 100”
在代码中可以设置:
1 2 3 4 5 spark = SparkSession.builder. \ appName("12_movie_demo.py" ). \ master("local[*]" ). \ config("spark.sql.shuffle.partitions" , 2 ). \ getOrCreate()
3.3.7 SparkSQL 数据清洗API 前面我们处理的数据实际上都是已经被处理好的规整数据,但是在大数据整个生产过程中,需要先对数据进行数据清洗,将杂乱无章的数据整理为符合后面处理要求的规整数据。
去重方法:dropDuplicates
功能:对DF的数据进行去重,如果重复数据有多条,取第一条
1 2 3 4 df.dropDuplicates().show() df.dropDuplicates(['age' ,'job' ]).show()
删除有缺失值的行方法 :dropna
功能:如果数据中包含null,通过dropna来进行判断,符合条件就删除这一行数据
1 2 3 4 5 6 7 8 9 df.dropna().show() df.dropna(thresh=3 ).show() df.dropna(thresh=2 ,subset=['name' ,'age' ]).show()
填充缺失值数据 fillna
功能:根据参数的规则,来进行null替换
1 2 3 4 5 6 df.fillna("loss" ).show() df.fillna("loss" ,subset=['job' ]).show() df.fillna({"name" :"未知姓名" ,"age" :1 ,"job" :"worker" }).show()
完整代码演示:13_data_clear_api.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Fif __name__ == '__main__' : spark = SparkSession.builder. \ appName("13_data_clear_api.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext """读取数据""" df = spark.read.format ("csv" ). \ option("sep" , ";" ). \ option("header" , True ). \ load("../data/input/sql/people.csv" ) df.dropDuplicates().show() df.dropDuplicates(['age' , 'job' ]).show() df.fillna("loss" ).show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 +-----+----+---------+ | name| age| job| +-----+----+---------+ |Alice| 9| null| | Ani| 11|Developer| |Alice| 9| Manager| |Alice|null| Manager| | Lily| 11| Manager| | Put| 11|Developer| |Jorge| 30|Developer| | Bob| 32|Developer| +-----+----+---------+ +-----+----+---------+ | name| age| job| +-----+----+---------+ |Alice|null| Manager| | Ani| 11|Developer| | Lily| 11| Manager| |Jorge| 30|Developer| | Bob| 32|Developer| |Alice| 9| null| |Alice| 9| Manager| +-----+----+---------+ +-----+----+---------+ | name| age| job| +-----+----+---------+ |Jorge| 30|Developer| | Bob| 32|Developer| | Ani| 11|Developer| | Lily| 11| Manager| | Put| 11|Developer| |Alice| 9| Manager| |Alice| 9| Manager| |Alice| 9| Manager| |Alice| 9| Manager| |Alice|loss| Manager| |Alice| 9| loss| +-----+----+---------+
3.3.8 DataFrame数据写出 统一API语法:
1 2 3 4 5 6 df.write.mode().format ().option(K,V).save(PATH)
完整代码演示:14_dataframe_write.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("14_dataframe_write.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext schema = StructType().add("user_id" , StringType(), nullable=True ). \ add("movie_id" , IntegerType(), nullable=True ). \ add("rank" , IntegerType(), nullable=True ). \ add("ts" , StringType(), nullable=True ) df = spark.read.format ("csv" ). \ option("sep" , "\t" ). \ option("header" , False ). \ option("encoding" , "utf-8" ). \ schema(schema=schema). \ load("../data/input/sql/u.data" ) df.select(F.concat_ws("---" , "user_id" , "movie_id" , "rank" , "ts" )). \ write. \ mode("overwrite" ). \ format ("text" ). \ save("../data/output/sql/text" ) df.write.mode("overwrite" ). \ format ("csv" ). \ option("sep" , ";" ). \ option("header" , True ). \ save("../data/output/sql/csv" ) df.write.mode("overwrite" ).\ format ("json" ).\ save("../data/output/sql/json" ) df.write.mode("overwrite" ).\ format ("parquet" ).\ save("../data/output/sql/parquet" )
3.3.9 DataFrame 通过JDBC读写数据库(MySQL示例) 读取JDBC是需要有驱动的,我们读取的是jdbc:mysql://这个协议,也就是读取的是mysql的数据
既然如此,就需要有msyql的驱动jar包给spark程序用
如果不给驱动jar包,会提示No suitable Driver
对于windows系统(使用本地解释器)(以Anaconda环境演示)
将jar包放在:Anaconda3的安装路径下\envs\虚拟环境\Lib\site-packages\pyspark\jars
对于Linux系统(使用远程解释器执行)(以Anaconda环境演示)
将jar包放在:Anaconda3的安装路径下/envs/虚拟环境/lib/python3.8/site-packages/pyspark/jars
代码演示:15_dataframe_jdbc.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("15_dataframe_jdbc.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext schema = StructType().add("user_id" , StringType(), nullable=True ). \ add("movie_id" , IntegerType(), nullable=True ). \ add("rank" , IntegerType(), nullable=True ). \ add("ts" , StringType(), nullable=True ) df = spark.read.format ("csv" ). \ option("sep" , "\t" ). \ option("header" , False ). \ option("encoding" , "utf-8" ). \ schema(schema=schema). \ load("../data/input/sql/u.data" ) df2 = spark.read.format ("jdbc" ). \ option("url" , "jdbc:mysql://Tnode1:3306/bigdata?useSSl=false&useUnicode=true" ). \ option("dbtable" , "movie_data" ). \ option("user" , "root" ). \ option("password" , "123456" ). \ load() df2.printSchema() df2.show() """ JDBC写出,会自动创建表的。 因为DadaFrame中有表结构信息,StructType记录的各个字段的名称类型和是否运行为空 """
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 root |-- user_id: string (nullable = true) |-- movie_id: integer (nullable = true) |-- rank: integer (nullable = true) |-- ts: string (nullable = true) +-------+--------+----+---------+ |user_id|movie_id|rank| ts| +-------+--------+----+---------+ | 196| 242| 3|881250949| | 186| 302| 3|891717742| | 22| 377| 1|878887116| | 244| 51| 2|880606923| | 166| 346| 1|886397596| | 298| 474| 4|884182806| | 115| 265| 2|881171488| | 253| 465| 5|891628467| | 305| 451| 3|886324817| | 6| 86| 3|883603013| | 62| 257| 2|879372434| | 286| 1014| 5|879781125| | 200| 222| 5|876042340| | 210| 40| 3|891035994| | 224| 29| 3|888104457| | 303| 785| 3|879485318| | 122| 387| 5|879270459| | 194| 274| 2|879539794| | 291| 1042| 4|874834944| | 234| 1184| 2|892079237| +-------+--------+----+---------+ only showing top 20 rows
注意:
jdbc连接字符串中,建议使用 useSSL=false 确保连接可以正常连接 (不使用SSL安全协议进行连接)
jdbc连接字符串中,建议使用 useUnicode=true 来确保传输中不出现乱码
save()不要填参数,没有路径,是写出数据库
dbtable属性:指定写出的表名
读出来的是自带schema,不需要设置schema,因为数据库就有schema
load()不需要加参数,没有路径,从数据库汇总读取的
dbtable:是指定读取的表名
3.3.10 总结
DataFrame 在结构层面上由StructField组成列描述,由StructType构造表描述。在数据层面上,Column对象记录列数据,Row对象记录行数据
DataFrame可以从RDD转换、Pandas DF转换、读取文件、读取JDBC等方法构建
spark.read.format()和df.write.format() 是DataFrame读取和写出的统一化标准API
SparkSQL默认在Shuffle阶段200个分区,可以修改参数获得最好性能
dropDuplicates可以去重、dropna可以删除缺失值、fillna可以填充缺失值
SparkSQL支持JDBC读写,可用标准API对数据库进行读写操作
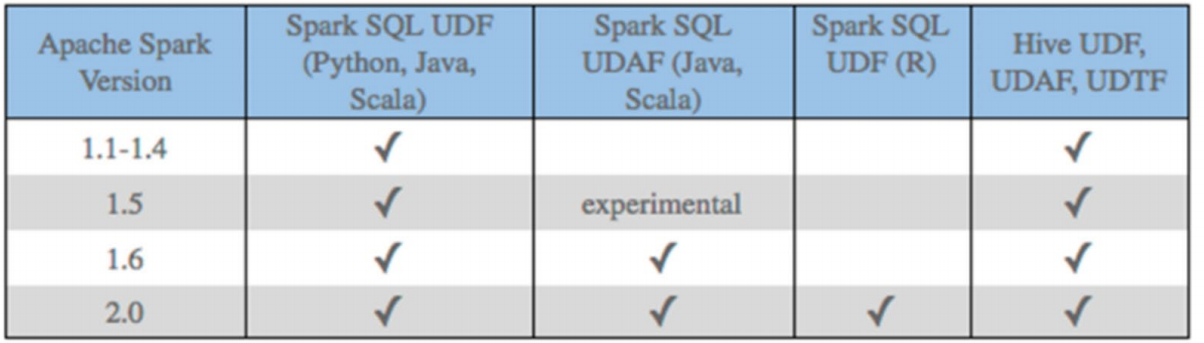
3.4 SparkSQL函数定义 3.4.1 SparkSQL定义UDF函数 无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛 。
回顾Hive中自定义函数有三种类型:
第一种:UDF(User-Defined-Function)函数
一对一的关系,输入一个值,经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
第二种:UDAF(User-Defined Aggregation Function)聚合函数
多对一的关系,输入个值输出一个值,通常与groupBy联合使用;
第三种:UDTF(User-Defined Table-Generating Functions)函数
一对多的关系,输入一个值输出多个值(一行变为多行)
用户自定义生成函数,有点像flatMap;
目前来说Spark框架各个版本及各种语言对自定义函数的支持:
在SparkSQL中,目前仅仅支持UDF函数和UDAF函数。目前Python仅支持UDF。
UDF定义方式有两种:
sparksession.udf.register()注册的UDF可以用于DSL和SQL,返回值用于DSL风格,传参内给的名字用于SQL风格pyspark.sql.functions.udf,仅能用于DSL风格
代码案例:16_udf_define.py
代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("16_udf_define.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([1 , 2 , 3 , 4 , 5 , 6 , 7 ]).map (lambda x: [x]) df = rdd.toDF(["num" ]) def num_multi_10 (num ): return num * 10 udf2 = spark.udf.register("udf1" , num_multi_10, IntegerType()) df.selectExpr("udf1(num)" ).show() df.select(udf2(df['num' ])).show() udf3 = F.udf(num_multi_10,IntegerType()) df.select(udf3(df['num' ])).show()
代码运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 +---------+ |udf1(num)| +---------+ | 10| | 20| | 30| | 40| | 50| | 60| | 70| +---------+ +---------+ |udf1(num)| +---------+ | 10| | 20| | 30| | 40| | 50| | 60| | 70| +---------+ +-----------------+ |num_multi_10(num)| +-----------------+ | 10| | 20| | 30| | 40| | 50| | 60| | 70| +-----------------+
注册一个返回值为ArrayType(数字\list)类型的UDF
代码案例:17_udf_return_array.py
代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerType, ArrayTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("17_udf_return_array.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([["hadoop spark flink" ], ["hadoop flink java" ]]) df = rdd.toDF(["line" ]) def split_line (data ): return data.split(" " ) udf2 = spark.udf.register("udf1" , split_line, ArrayType(StringType())) df.select(udf2(df['line' ])).show() df.createTempView("lines" ) spark.sql("SELECT udf1(line) FROM lines" ).show(truncate=False ) udf3 = F.udf(split_line, ArrayType(StringType())) df.select(udf3(df['line' ])).show(truncate=False )
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 +--------------------+ | udf1(line)| +--------------------+ |[hadoop, spark, f...| |[hadoop, flink, j...| +--------------------+ +----------------------+ |udf1(line) | +----------------------+ |[hadoop, spark, flink]| |[hadoop, flink, java] | +----------------------+ +----------------------+ |split_line(line) | +----------------------+ |[hadoop, spark, flink]| |[hadoop, flink, java] | +----------------------+
注意:数组或者list类型,可以使用spark的ArrayType来描述即可
声明ArrayType要类似这样:ArrayType(StringType()),在ArrayType中传入数组内的数据类型
注册一个返回值为字典类型的UDF
代码案例:18_udf_return_dict.py
代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import stringfrom pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerType, ArrayTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("18_udf_return_dict.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([[1 ], [2 ], [3 ]]) df = rdd.toDF(["num" ]) def process (data ): return {"num" : data, "letters" : string.ascii_letters[data]} """ UDF的返回值是字典的话,需要用StructType来接收 """ udf1 = spark.udf.register("udf1" , process, StructType().add("num" , IntegerType(), nullable=True ). \ add("letters" , StringType(), nullable=True ) ) df.selectExpr("udf1(num)" ).show(truncate=False ) df.select(udf1(df['num' ])).show(truncate=False )
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 +---------+ |udf1(num)| +---------+ |{1, b} | |{2, c} | |{3, d} | +---------+ +---------+ |udf1(num)| +---------+ |{1, b} | |{2, c} | |{3, d} | +---------+
注意:字典类型返回值,可以用StructType来进行描述
StructType是一个普通的Spark支持的结构化类型
只是可以用在:
DF中用于描述Schema
UDF中用于描述返回值是字典的数据
用mapPartitions API 完成UDAF聚合
代码案例:19_udaf_by_rdd.py
代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import stringfrom pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerType, ArrayTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("19_udaf_by_rdd.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([1 , 2 , 3 , 4 , 5 ], 3 ) df = rdd.map (lambda x: [x]).toDF(['num' ]) single_partition_rdd = df.rdd.repartition(1 ) def process (iter sum = 0 for row in iter : sum += row['num' ] return [sum ] print (single_partition_rdd.mapPartitions(process).collect())
运行结果:
注意:
使用UDF两种方式的注册均可以。
唯一需要注意的就是:返回值类型一定要有合适的类型来声明
返回 int 可以用IntergerType
返回小数,可以用FloatType或者DoubleType
返回数组list 可以用ArrayType描述
返回字典 可以用StructType描述
…..
这些Spark内置的数据类型均存储在:
pyspark.sql.types包中。
3.4.2 SparkSQL使用函数窗口 开窗函数 :
开窗函数的引入是为了既显示聚集前的数据,又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。
窗口函数的语法:
代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import stringfrom pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StructType, StringType, IntegerType, ArrayTypeif __name__ == '__main__' : spark = SparkSession.builder. \ appName("20_window_function.py" ). \ master("local[*]" ). \ getOrCreate() sc = spark.sparkContext rdd = sc.parallelize([ ('张1' , 'class_1' , 99 ), ('张2' , 'class_2' , 35 ), ('张3' , 'class_3' , 57 ), ('张4' , 'class_4' , 12 ), ('张5' , 'class_5' , 99 ), ('张6' , 'class_1' , 90 ), ('张7' , 'class_2' , 91 ), ('张8' , 'class_3' , 33 ), ('张9' , 'class_4' , 55 ), ('张10' , 'class_5' , 66 ), ('张11' , 'class_1' , 11 ), ('张12' , 'class_2' , 33 ), ('张13' , 'class_3' , 36 ), ('张14' , 'class_4' , 79 ), ('张15' , 'class_5' , 90 ), ('张16' , 'class_1' , 90 ), ('张17' , 'class_2' , 90 ), ('张18' , 'class_3' , 11 ), ('张19' , 'class_1' , 11 ), ('张20' , 'class_2' , 3 ), ('张21' , 'class_3' , 99 ), ]) schema = StructType().add("name" , StringType()). \ add("class" , StringType()). \ add("score" , IntegerType()) df = rdd.toDF(schema) df.createTempView("stu" ) spark.sql(""" select *,avg(score) over() as avg_score from stu """ ).show() spark.sql(""" SELECT *,ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank, DENSE_RANK() OVER(PARTITION BY class ORDER BY score DESC) AS dense_rank, RANK() OVER(ORDER BY score) AS rank FROM stu """ ).show() spark.sql(""" select * ,NTILE(6) OVER(ORDER BY score desc) AS NTILE_result from stu """ ).show()
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 +----+-------+-----+------------------+ |name| class|score| avg_score| +----+-------+-----+------------------+ | 张1|class_1| 99|56.666666666666664| | 张2|class_2| 35|56.666666666666664| | 张3|class_3| 57|56.666666666666664| | 张4|class_4| 12|56.666666666666664| | 张5|class_5| 99|56.666666666666664| | 张6|class_1| 90|56.666666666666664| | 张7|class_2| 91|56.666666666666664| | 张8|class_3| 33|56.666666666666664| | 张9|class_4| 55|56.666666666666664| |张10|class_5| 66|56.666666666666664| |张11|class_1| 11|56.666666666666664| |张12|class_2| 33|56.666666666666664| |张13|class_3| 36|56.666666666666664| |张14|class_4| 79|56.666666666666664| |张15|class_5| 90|56.666666666666664| |张16|class_1| 90|56.666666666666664| |张17|class_2| 90|56.666666666666664| |张18|class_3| 11|56.666666666666664| |张19|class_1| 11|56.666666666666664| |张20|class_2| 3|56.666666666666664| +----+-------+-----+------------------+ only showing top 20 rows +----+-------+-----+---------------+----------+----+ |name| class|score|row_number_rank|dense_rank|rank| +----+-------+-----+---------------+----------+----+ | 张1|class_1| 99| 1| 1| 19| | 张6|class_1| 90| 5| 2| 14| |张16|class_1| 90| 7| 2| 14| |张11|class_1| 11| 18| 3| 2| |张19|class_1| 11| 20| 3| 2| | 张7|class_2| 91| 4| 1| 18| |张17|class_2| 90| 8| 2| 14| | 张2|class_2| 35| 14| 3| 8| |张12|class_2| 33| 16| 4| 6| |张20|class_2| 3| 21| 5| 1| |张21|class_3| 99| 3| 1| 19| | 张3|class_3| 57| 11| 2| 11| |张13|class_3| 36| 13| 3| 9| | 张8|class_3| 33| 15| 4| 6| |张18|class_3| 11| 19| 5| 2| |张14|class_4| 79| 9| 1| 13| | 张9|class_4| 55| 12| 2| 10| | 张4|class_4| 12| 17| 3| 5| | 张5|class_5| 99| 2| 1| 19| |张15|class_5| 90| 6| 2| 14| +----+-------+-----+---------------+----------+----+ only showing top 20 rows +----+-------+-----+------------+ |name| class|score|NTILE_result| +----+-------+-----+------------+ | 张1|class_1| 99| 1| | 张5|class_5| 99| 1| |张21|class_3| 99| 1| | 张7|class_2| 91| 1| | 张6|class_1| 90| 2| |张15|class_5| 90| 2| |张16|class_1| 90| 2| |张17|class_2| 90| 2| |张14|class_4| 79| 3| |张10|class_5| 66| 3| | 张3|class_3| 57| 3| | 张9|class_4| 55| 3| |张13|class_3| 36| 4| | 张2|class_2| 35| 4| | 张8|class_3| 33| 4| |张12|class_2| 33| 5| | 张4|class_4| 12| 5| |张11|class_1| 11| 5| |张18|class_3| 11| 6| |张19|class_1| 11| 6| +----+-------+-----+------------+
3.4.3 总结
SparkSQL支持UDF和UDAF定义,但在Python中,暂时只能定义UDF
UDF定义支持2种方式,1:使用SparkSession对象构建。2:使用functions包中提供的UDF API构建。要注意,方式1可用DSL和SQL风格,方式2可用于DSL风格。
SparkSQL支持窗口函数使用,常用SQL中的窗口函数均支持,如聚合窗口、排序窗口、NTILE分组窗口等。


















 wechat
wechat alipay
alipay